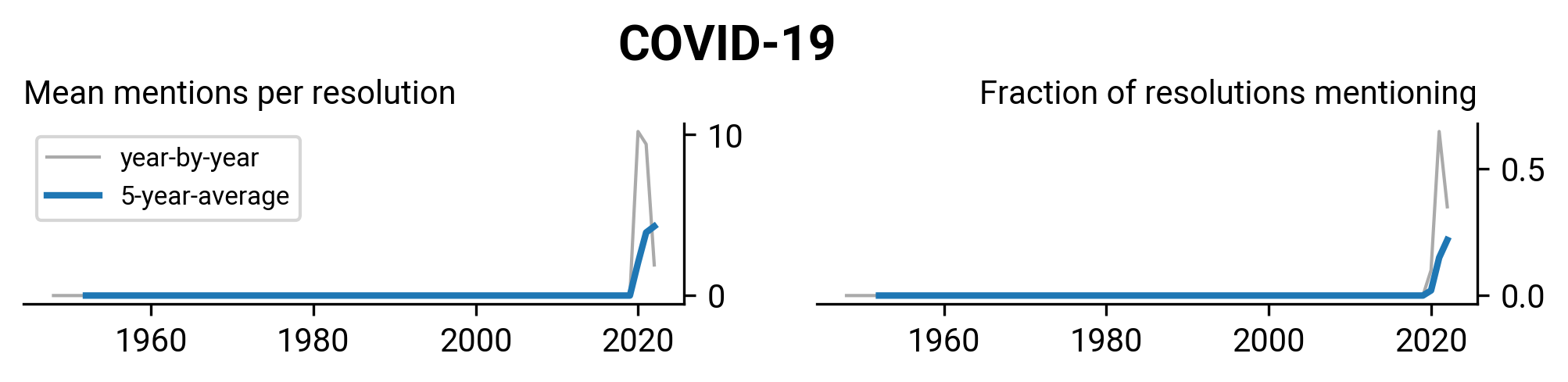
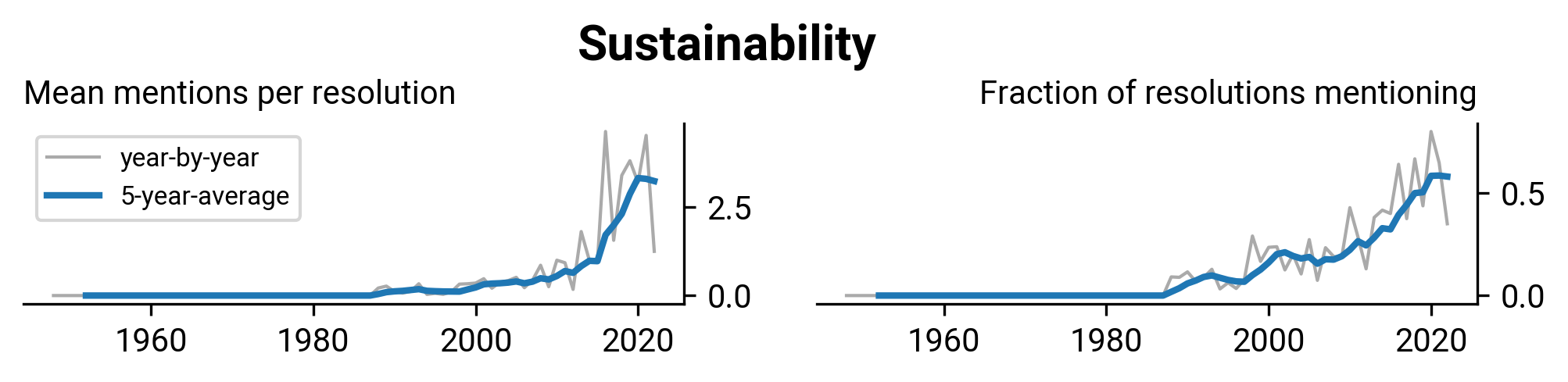
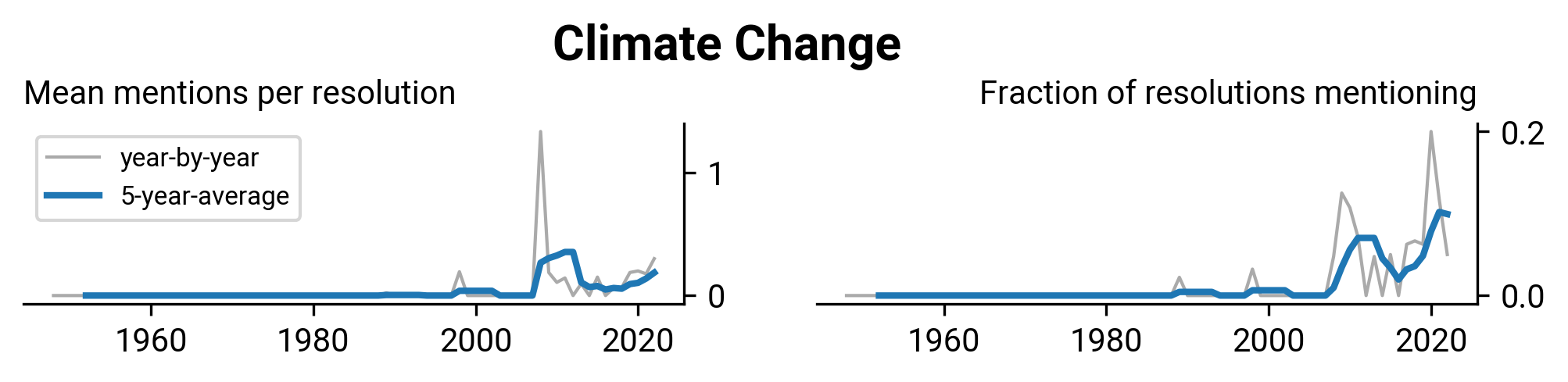
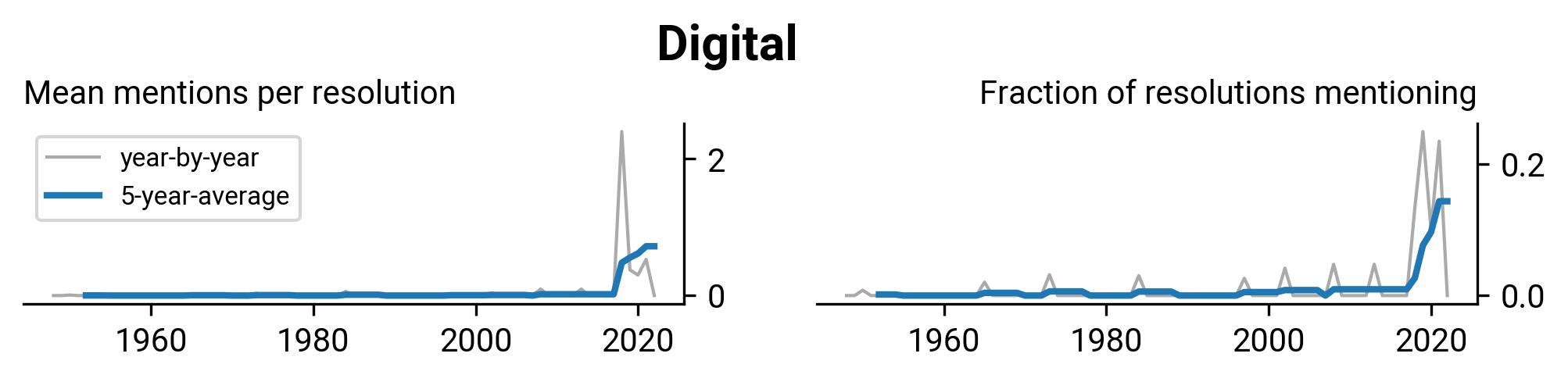
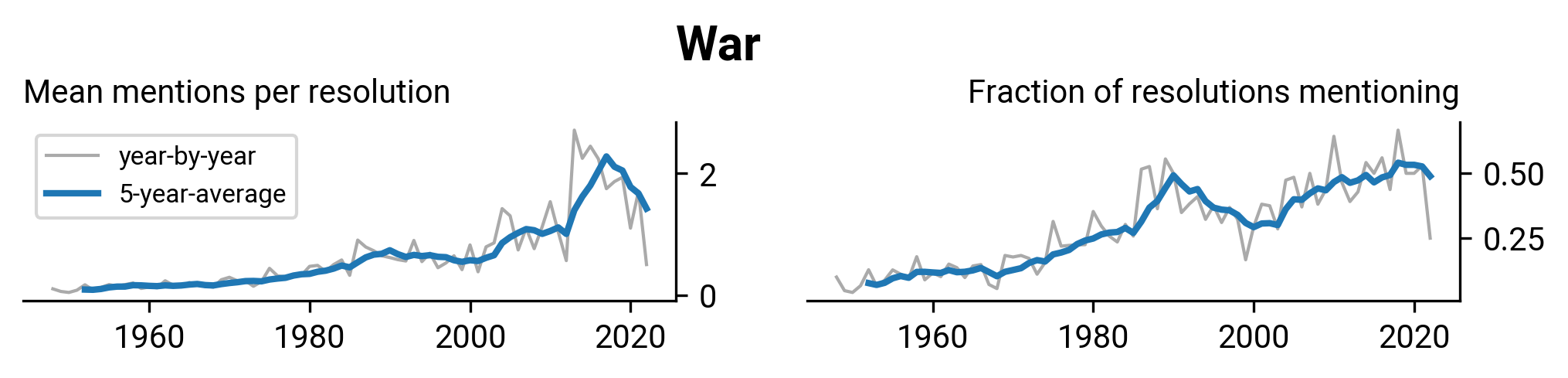
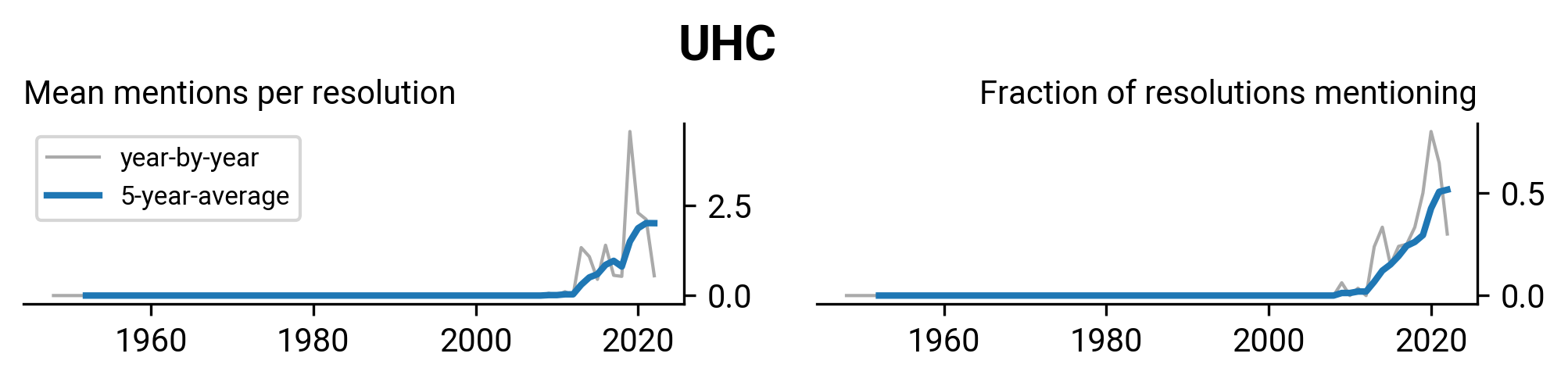
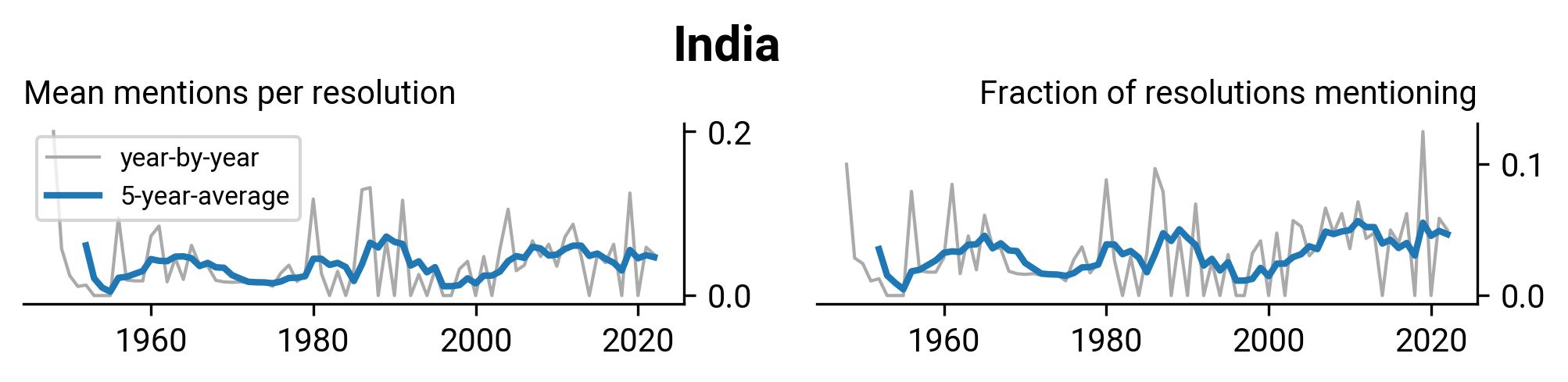
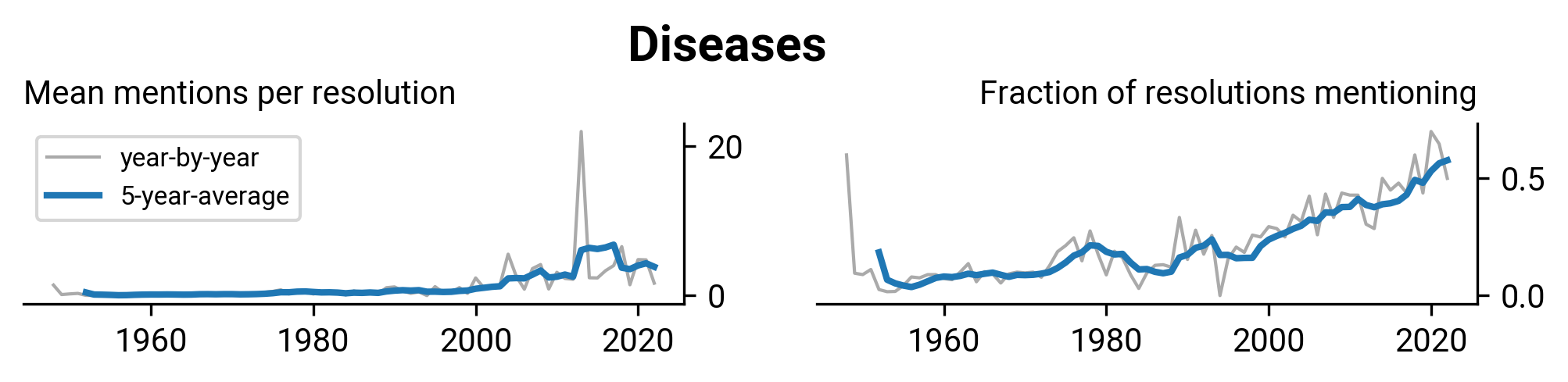
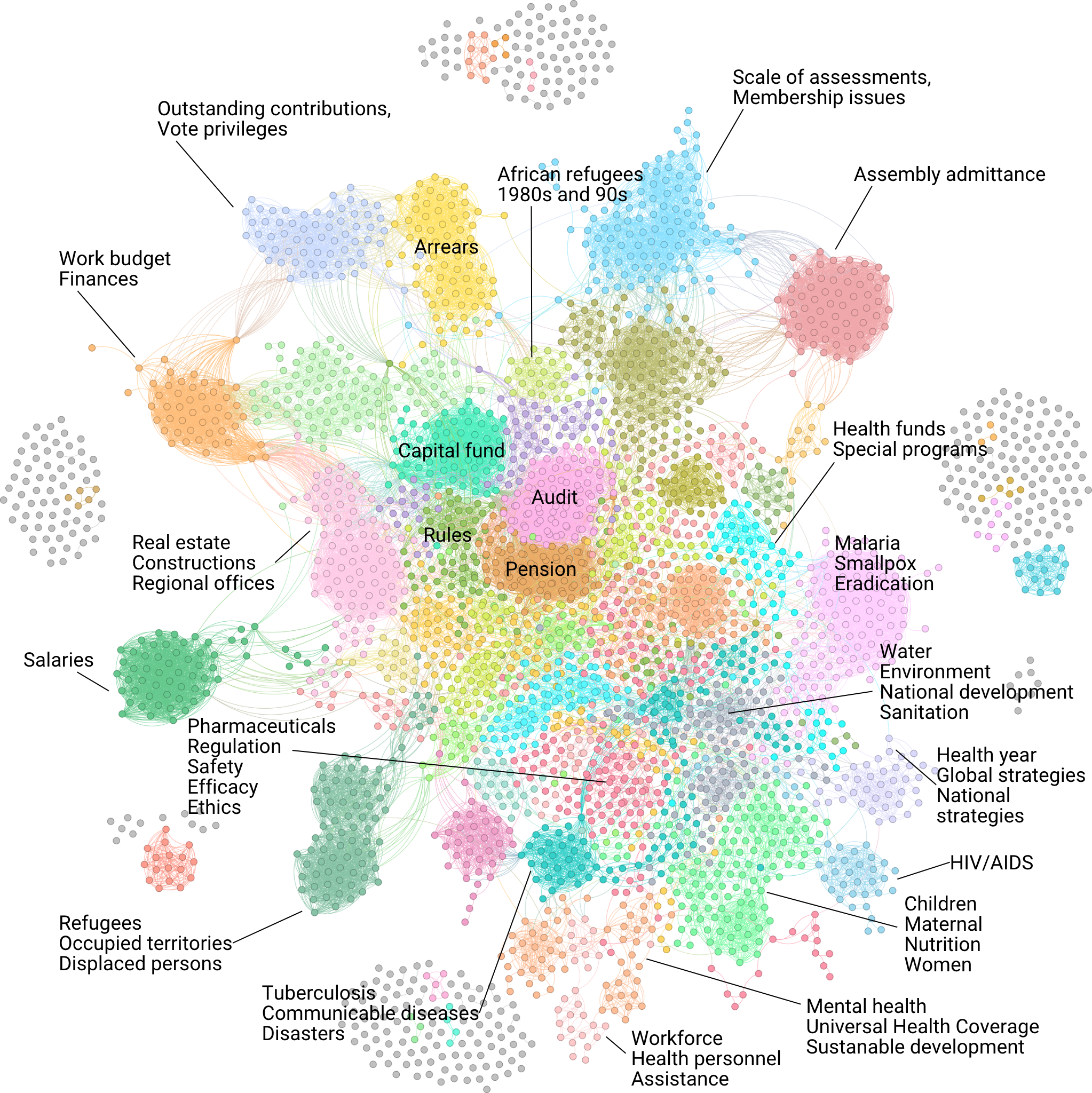
WHA2.27: Insulin
Topics: gener studi, advis, explor, manufactur, possibl, programm adopt
WHA4.48: WHO seals
Topics: supplement, ona, assembl suspens, toit, inconform, suggest, organ request, gener submit, fund health, gener implement
WHA6.56: Special benefit for retiring Director-General
Topics: staff pension, pension, save, work capit, capit fund, capit, contract, occur, budget estim, sum
WHA15.34: Malaria eradication special account
Topics: malaria, erad, special account, erad programm, cash, voluntari contribut, transit, programm request, laid, regularli
WHA23.18: Headquarters accommodation: report on financing
Topics: headquart, real estat, estat, expens, real, sum, reflect, main, share, outcom
WHA29.37: Amendments to the rules of procedures of the World Health Assembly
Topics: point, presid, deleg, rule procedur, associ member, add, appeal, aris, follow, statement
WHA29.22: Report on the world health situation
Topics: health situat, publish, content, analysi, programm work, gener programm, improv qualiti, subsequ health, report request, russian
WHA31.26: Health and medical assistance to Lebanon
Topics: lebanon, creat, assist provid, injuri, assembl mind, mainten, previou resolut, organ health, peac secur, express appreci
WHA32.22: Collaboration with the United Nations system: cooperation with newly independent and emerging States in Africa: liberation struggle in Southern Africa
Topics: assembl implement, elect, health year, independ, resolut health
WHA34.33: Collaboration with the United Nations system: cooperation with newly independent and emerging States in Africa: special programme of cooperation with the Republic of Chad
Topics: chad, special programm, spirit, inclos, technic financi, health situat, programm request, invit member, possibl, region director
WHA35.13: Transfer of the Regional Office for the Eastern Mediterranean
Topics: advantag, gener prepar, effect implement, goal health, submit health, opinion, resolut ebr, maximum, believ, implement health
WHA36.17: Real estate fund and Headquarters accommodation
Topics: real estat, estat, real, headquart, main, region offic, construct, casual incom, casual, water
WHA46.12: Assessment of the Czech Republic and the Slovak Republic
Topics: assess rate, nation scale, rate establish, latest, state concern, fix, replac, budgetari, share, scale assess
WHA47.1: Rights and privileges of South Africa
Topics: south africa, south, grant, activ health, democrat, elect, instal, anew, constitut health, fulfil
WHA49.21: Collaboration within the United Nations system and with other intergovernmental organizations: strengthening of the coordination of emergency humanitarian assistance
Topics: humanitarian, document rec, advocaci, disast, prepared, rec, draw attent, anew, assembl resolut, defin
WHA54.9: Assessment of the Federal Republic of Yugoslavia
Topics: yugoslavia, feder, scale assess, assembl establish, nation scale, latest, principl establish, confirm
WHA71.12: Salaries of staff in ungraded positions and of the Director-General
Topics: salari, net, annum, remuner, board regard, note recommend, gener establish, gener region, region director, post
WHA75.10: Status of collection of assessed contributions, including Member States in arrears in the payment of their contributions to an extent that would justify invoking Article 7 of the Constitution of the World Health Organization
Topics: constitut health, open, arrear, invok articl, justifi, invok, vote privileg, suspend, privileg, cameroon